There’s a yellow elephant quietly powering some of the most data-intensive systems on the planet. You probably haven’t thought about it. You’ve almost certainly benefited from it.
Topics
Table of Contents
Hadoop, yes, that’s how you pronounce it, HAD-oop, is the open-source framework that made “big data” go from buzzword to actual infrastructure. It was the technology that let Yahoo, Facebook, and LinkedIn stop drowning in data and start making sense of it. And while newer tools have grabbed the spotlight, Hadoop is far from dead.
If you’re a student exploring data engineering, a professional trying to understand your company’s data stack, or just someone curious about how modern businesses handle billions of records, this guide is for you.
What Is Hadoop?
Apache Hadoop is an open-source software framework for storing and processing massive datasets across clusters of computers using simple programming models. The official home is github.com/apache/hadoop, maintained under the Apache Software Foundation.
The name, for those wondering, doesn’t stand for anything. Doug Cutting, one of Hadoop’s creators, named it after his son’s yellow stuffed elephant toy. That’s the origin of the iconic Hadoop elephant logo, arguably one of the most recognisable mascots in enterprise technology.
Cutting developed Hadoop in the mid-2000s alongside Mike Cafarella while working at Yahoo, drawing on concepts from Google’s published research on the Google File System and MapReduce. In 2006, it became a standalone Apache project. By 2008, Yahoo was running it on a 10,000-core cluster. The big data era had officially begun.
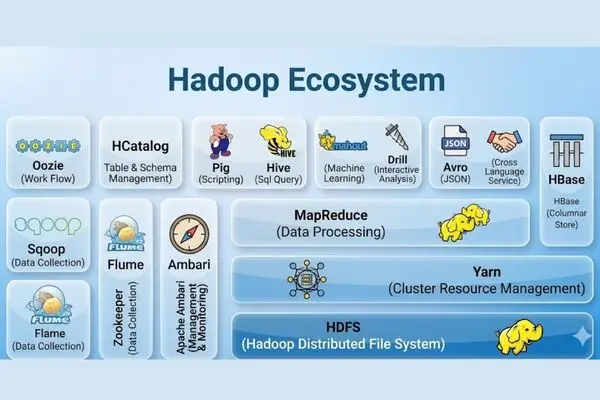
Hadoop Architecture: How It Actually Works
Understanding what Hadoop does requires a quick look at how it’s built. The architecture has two core components that work in tandem.
HDFS, The Storage Layer
The Hadoop Distributed File System (HDFS) is where data lives. It breaks large files into smaller blocks (typically 128MB each) and distributes them across multiple machines in a cluster. Each block is replicated across multiple nodes, usually 3, so if one node fails, the data remains safe.
This is fundamentally different from a traditional database, storing everything in one place. HDFS was designed for fault tolerance at scale, which is exactly what you need when you’re dealing with petabytes of data spread across thousands of commodity servers.
MapReduce, The Processing Layer
MapReduce is the programming model that processes data stored in HDFS. It works in two phases:
- Map phase: Takes raw input data and converts it into key-value pairs
- Reduce phase: Aggregates and summarises those pairs into a final output
Think of it like a library research project. The Map phase is when every researcher independently pulls relevant books and highlights key passages. The Reduce phase is when everyone combines their highlights into a single coherent summary. The work runs in parallel across many machines, enabling the processing of enormous datasets.
A modern Hadoop cluster also includes YARN (Yet Another Resource Negotiator), which manages resource allocation across applications, and a growing ecosystem of tools, Hive, Pig, HBase, Spark, and more, that sit on top of the core framework.
What Is Hadoop Used For?
This is where the rubber meets the road. Hadoop’s real-world applications span nearly every major industry.
Retail and E-Commerce
Walmart processes more than 2.5 petabytes of customer transaction data every hour. They use Hadoop to analyse purchasing behaviour, optimise inventory, and fine-tune pricing in near real time. Without a distributed processing framework, that kind of analysis would be computationally impossible.
Financial Services
Banks and fintech companies use Hadoop for fraud detection, risk modelling, and regulatory compliance. JPMorgan Chase, for instance, runs Hadoop clusters to analyse transaction patterns across millions of accounts, flagging anomalies that smaller systems would miss entirely.
Healthcare and Research
Genomics is perhaps the most striking use case. A single human genome contains roughly 3 billion base pairs of data. Processing genetic data for large patient populations requires exactly the kind of distributed storage and computation that Hadoop was built for. Research institutions use it to identify disease markers and analyse treatment outcomes at the population scale.
Media and Entertainment
Before building much of its infrastructure around cloud-native tools, Netflix relied heavily on Hadoop for log processing and recommendation modelling. Every time the platform surfaces a show you didn’t know you’d love, that suggestion is the result of processing behavioural data across hundreds of millions of viewers.
Blockchain Technology and Its 4 Types: The Best Guide to Understanding Digital Ledger
Is Hadoop SQL or NoSQL?
This question comes up constantly, and the answer is: neither, exactly, though it works with both.
Hadoop itself is a storage and processing framework, not a database. However, HBase, a component of the Hadoop ecosystem, is a NoSQL database that runs on HDFS and provides real-time read/write access to large datasets.
On the SQL side, Apache Hive allows analysts to query data stored in HDFS using a SQL-like language called HiveQL. So if your team knows SQL, they can interact with Hadoop data without learning MapReduce directly.
In practice, Hadoop acts as a foundation that supports both paradigms, depending on the tools layered on top of it.
Is Hadoop Used in AI?
Yes, though usually as infrastructure rather than the AI engine itself.
Hadoop excels at storing and preprocessing the enormous training datasets that machine learning models require. Before you can train a model to recognise speech, classify images, or detect fraud, someone has to gather, clean, and organise billions of labelled data points. That’s often where Hadoop fits.
Companies running AI pipelines at scale frequently use HDFS as a data lake, a central repository for raw, unstructured data, while tools like Apache Spark handle the faster, iterative computations required for model training.
Hadoop vs Spark: The Honest Comparison
If you’ve spent any time researching big data, you’ve seen this comparison framed as a battle. The reality is more nuanced.
Apache Spark was designed to overcome Hadoop MapReduce’s biggest weakness: speed. MapReduce writes intermediate results to disk between processing steps, resulting in significant I/O overhead. Spark processes data in-memory, making it roughly 10 to 100 times faster for many workloads.
For iterative algorithms, the kind used in machine learning, where the same data passes through a model hundreds of times, Spark wins decisively.
But here’s what often gets left out: Spark doesn’t have its own storage system. It typically runs on top of HDFS. The two tools are far more complementary than competitive. Most mature big data architectures use both: Hadoop for storage and batch ingestion, Spark for fast processing and analytics.
The real story isn’t Hadoop vs Spark. It’s Hadoop + Spark as a stack.
Why Is Hadoop “No Longer Used”, And Why That Narrative Is Overstated
Type “is Hadoop dead” into any search engine and you’ll find plenty of pessimistic takes. The reality deserves more precision.
What has genuinely declined is Hadoop’s dominance as the default big data solution. Cloud platforms, AWS with S3 and EMR, Google Cloud with BigQuery, and Azure with its Data Lake, offer managed services that handle much of what Hadoop did without requiring companies to maintain their own clusters. For organisations without dedicated data engineering teams, cloud-native solutions are simply more practical.
But “easier alternatives exist” is not the same as “Hadoop is dead.” Thousands of large enterprises still run Hadoop clusters, particularly those with data sovereignty requirements, on-premise infrastructure commitments, or existing investments too large to migrate overnight.
Hadoop skills remain genuinely valuable in the financial services, government, telecommunications, and healthcare industries, where data remains on-premises and scale demands remain enormous.
How to Get Started: Hadoop Download and First Steps
Ready to get hands-on? Here’s a practical path that works whether you’re on Linux, Mac, or Windows.
Hadoop Download and Setup
The official Apache Hadoop download is available at hadoop.apache.org. For Hadoop download on Windows, the setup is slightly more involved; you’ll need to install Windows Subsystem for Linux (WSL2) or use a pre-configured virtual machine. The Apache Hadoop GitHub repository has up-to-date documentation and source code.
For beginners, the fastest path to a working environment is Docker. Several maintained Docker images let you run a single-node Hadoop cluster in minutes without touching system configuration.
Learning Path for Beginners
Week 1–2: Understand the concepts. Before touching any code, get clear on the fundamentals of distributed systems, what HDFS actually does, and how MapReduce processes data. The official Apache documentation is dense but accurate. Supplement it with YouTube walkthroughs.
Week 3–4: Install and explore. Get Hadoop running locally in pseudo-distributed mode. Load a dataset, run a basic word count MapReduce job, and browse the HDFS web interface. Hands-on time accelerates understanding faster than reading alone.
Month 2: Learn the ecosystem. Pick one adjacent tool, start with Hive if you know SQL, or Spark if you want faster processing. Build a small project: process a public dataset, run some queries, and visualise results.
Month 3+: Go deeper on architecture. YARN, data ingestion with Apache Sqoop or Flume, and cluster monitoring with Apache Ambari are natural next steps for anyone heading toward a data engineering role.
Conclusion
Hadoop changed what was possible in data engineering. It made petabyte-scale storage and processing accessible to organisations that couldn’t afford Google-scale custom infrastructure. The yellow elephant opened a door, and an entire industry walked through it.
The tools have evolved. Cloud services have absorbed many of Hadoop’s use cases. Spark has become the preferred processing engine for speed-sensitive workloads. But the underlying principles Hadoop established, distributed storage, fault-tolerant replication, and parallel processing, remain the foundation of modern big data infrastructure.
Understanding Hadoop isn’t just historical trivia. It’s the context that makes the rest of the data engineering world make sense.
Whether you’re downloading it today to run your first MapReduce job or trying to understand why your company still runs it in production, the yellow elephant is worth knowing.
Frequently Asked Questions
What is Hadoop used for?
Hadoop is used to store and process extremely large datasets across clusters of computers. Common applications include log analysis, fraud detection, genomics research, retail analytics, and serving as a data lake for AI and machine learning pipelines. Industries like finance, healthcare, retail, and media rely on it for big data workloads.
How do you pronounce Hadoop?
Hadoop is pronounced HAD-oop, two syllables, with emphasis on the first. The name comes from Doug Cutting’s son’s stuffed toy elephant, which also inspired the iconic Hadoop elephant logo.
Is Hadoop SQL or NoSQL?
Hadoop is neither; it’s a storage and processing framework. However, it supports both paradigms through ecosystem tools. Apache Hive provides SQL-like querying over HDFS data, while HBase is a NoSQL database built on top of HDFS for real-time access.
Is Hadoop dead?
Not dead, but no longer the default first choice for new big data projects. Cloud-native alternatives such as AWS EMR, Google BigQuery, and Azure Data Lake have been adopted for many use cases. However, Hadoop remains widely used in large enterprises, particularly in regulated industries with on-premise infrastructure requirements.
What is the difference between Hadoop and Spark?
Hadoop MapReduce processes data by writing intermediate results to disk, making it slower but suitable for large batch jobs. Apache Spark processes data in-memory, making it significantly faster, especially for iterative tasks like machine learning. Most modern data architectures use both Hadoop (HDFS) for storage and Spark for processing.
Where can I download Hadoop?
The official Apache Hadoop download is available at hadoop.apache.org. The source code and documentation are also maintained on the Apache Hadoop GitHub repository at github.com/apache/hadoop.